How it works
How exactly does our system work? We propose the Alien Engine, a set of nodal pipelines to connect datasets to AI inference engines. In order for our system to work across all AI modalities, we needed to create a universal design principle. It can be summarized in three steps, dataset processing, training and streaming (inference).
1. Dataset Processing
This step takes a dataset and prepares it for AI processing, this can be OCR, captioning, trans-cription, etc. Each entry is processed and updated with the preprocessing information.
2. Training
This step is the central pillar of our AI augmen-tation strategy. We build upon foundational models and depending on the inference required, can finetune a LoRa, embed entries into vectors, or encapsulate a KV Cache.
3. Streaming
This is the final step and crucial step, it exposes the results of the training step through a fully custo-mizable endpoint, exposing parameters, and returning inference results.
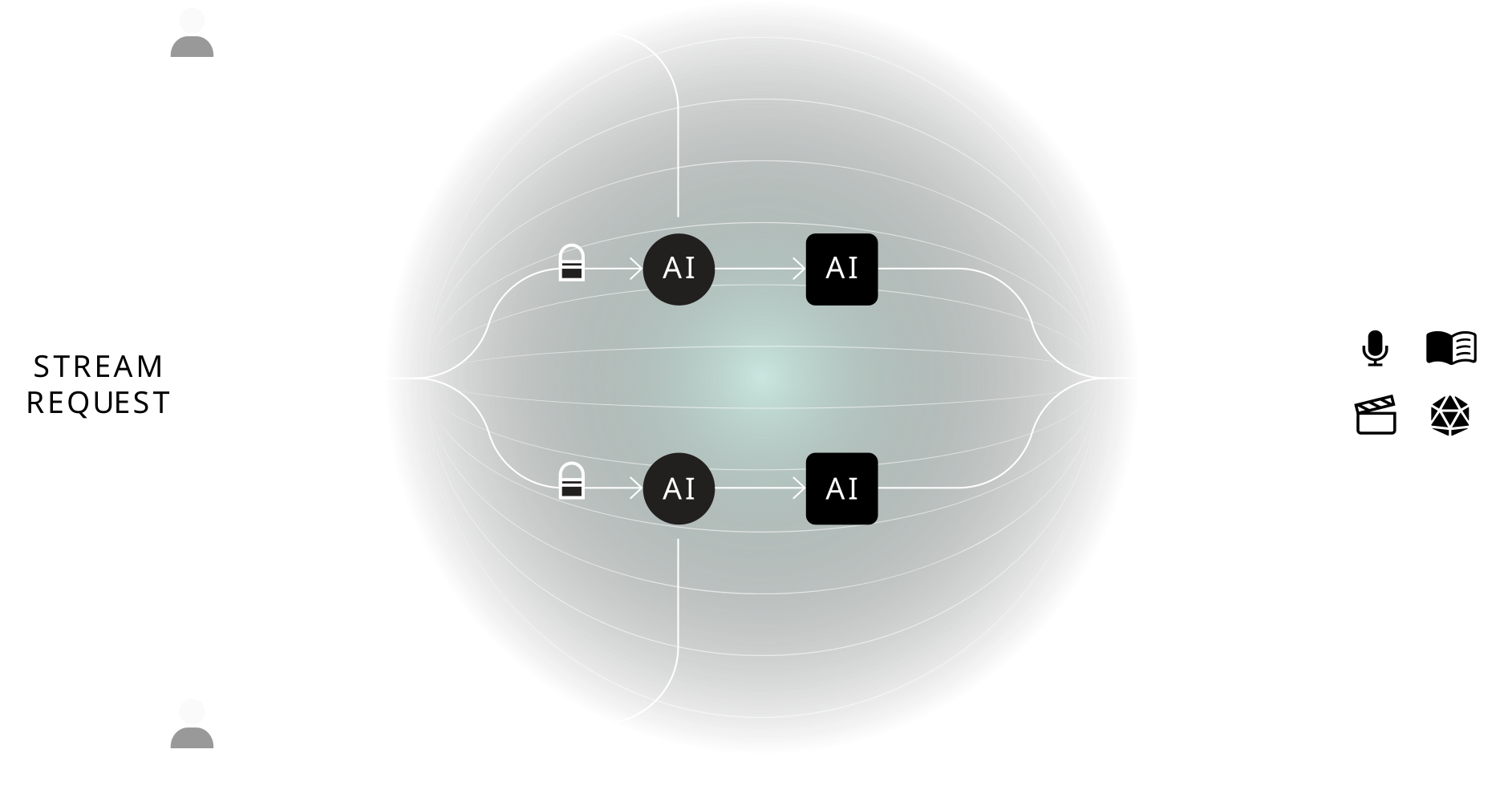
But our engine doesn’t stop at one dataset, indeed, once processing and training have been executed, it becomes possible to create multi-dataset, multi-AI, and multi-modal streaming endpoints. Imagine a LLM accessing a book series content, generating insights, outputting it as speech in your favorite voice.
Moreover, due to our nodal infrastructure, the Alien Engine is natively compatible with all GPU cloud providers and integrates seamlessly with the open source AI ecosystem.
No more will a dataset be confined to a 2 year old model, with a few clicks, the latest endpoints can be added to create a finetune on the best foundational model and expose it as an inference endpoint.
Another major advantage of our system is that it keeps track of dataset usages atomically. Indeed, our nodal infrastructure tracks each nodal execution, and each node output, therefore, royalties, usages and permissions can always be computed and enforced.
Use cases
Transcribing hindi with whisper
Transcribing Hindi with Whisper: A callbot company wants to expand to India, but while Hindi is a major language, no AI model is trained on it for transcription. With Alien, it becomes possible to plug all Hindi voice datasets onto the finetuning of a LoRa for Whisper, a transcription AI model. A processing pipeline prepares the data by sampling the voices, and tokenizing the text. A training pipeline creates a LoRa for Whisper, and finally, a Streaming pipeline exposes transcription as a service through an API endpoint. Each call to the endpoint is counted, and usages flow back to each dataset proportionally.
Talk with science
Talk with science: An AI company that provides agentic search for education expands to the Indian market. To continue our example above, to create a simple question and answer chatbot, one would then need to plug into a vast amount of knowledge. Using scientific paper datasets, a streaming pipeline could first transcribe the voice, search through a collection of documents in a RAG system, then call an LLM, synthesize a voice and finally stream the output to the user. Once again, each use of the data is tracked allowing for royalties and revenue to be distributed fairly.
The possibilities are endless, and the Alien Engine grows in sync with the AI ecosystem. By empowering users to create their own pipelines, we support the creation of multiple AI systems, while guaranteeing a fair compensation for right holders.